Introduction to PostgreSQL physical storage
November 9, 2015
I initially wrote this post for myself, I wanted to understand enough about the underlying physical storage to be able to grasp other concepts which can affect your database. This post is probably more aimed to people with similar interests, I will try to keep it accurate but the aim is to make it simpler to understand so I may overlook some details.
Should you know about how Postgres handle the physical storage? Maybe not, but knowing how it works can be useful if you need to investigate some problems.
PostgreSQL has a chapter on the subject but personally I had to dive in extra resources to get my head around it. I found difficult to navigate through multiple parts of the documentation and external resources, so this is my attempt to gather the essential in a single post. In this post, I didn't bother to rewrite everything so in some place I reused paragraphs from the official documentation.
At the time of this article, the current version of Postgres is 9.5, it's possible that the information in this post to be voided in a future release.
To illustrate the examples of this post, we will be assuming that we have a database called foo which contain a table called bar.
A bit of terminology
Once you dive into the documentation about storage then you start to hit some less common terms like relations, tuple, heap, block, page... Let me try to demystify what they mean:
- a
tupleor anitemis a synonym for a row - a
relationis a synonym for a table - a
filenodeis an id which represent a reference to a table or an index. - a
blockandpageare equals and they represent a 8kb segment information the file storing the table. - a
heaprefer toheap file. Heap files are lists of unordered records of variable size. Although sharing a similar name, heap files are different from heap data structure. CTIDrepresent the physical location of the row version within its table.CTIDis also a special column available for every tables but not visible unless specifically mentioned. It consists of a page number and the index of an item identifier.OIDstands for Object Identifier.database cluster, we call a database cluster the storage area on disk. A database cluster is a collection of databases that is managed by a single instance of a running database server.VACCUM, PostgreSQL databases require periodic maintenance known as vacuuming
Don't get surprised if you hit this terms in the rest of this post. In few places, I simplified the content when it was possible.
Where is my database stored
The data files used by a database cluster are stored together within the cluster's data directory, commonly referred to as PGDATA (after the name of the environment variable that can be used to define it). PGDATA can have different location base on your OS or installation.
For each database in the cluster, there is a subdirectory within PGDATA/base, named after the database's OID in pg_database. This subdirectory is the default location for the database's files.
You can run the following query if you want to list the OID for each database in your cluster.
select oid, datname from pg_database;
oid | datname
-------+-------------
1 | template1
12398 | template0
12403 | postgres
17447 | fooIf you are looking for the OID of a specific database then you add a WHERE clause to the query:
select oid, datname from pg_database WHERE datname = 'foo';The other way to find the OID of a database is using the command line oid2name. It's a utility program to examine the file structure used by PostgreSQL for more information on how to use it check the documentation
$> oid2name
All databases:
Oid Database Name Tablespace
----------------------------------
17447 foo pg_default
12398 template0 pg_default
1 template1 pg_defaultThe OID's above may be completely different in your system, but now we know that all the files concerning the database foo are stored in PGDATA/base/17447. If you ask yourself in which database, tables as pg_database are stored then they are not in PGDATA/base but in PGDATA/global.
Now, we know where to find the database in our file system so let try to figure out where to find our table.
Where tables are stored
Each table is stored in a separate file. For ordinary relations, these files are named after the table or index's filenode number, which can be found in the column relfilenode of the table pg_class. pg_class is system table which exist in the pg_catalog schema.
When a table exceeds 1 GB, it is divided into gigabyte-sized segments. The first segment's file name is the same as the filenode; subsequent segments are named filenode.1, filenode.2, etc. This arrangement avoids problems on platforms that have file size limitations.
A table's filenode often matches its OID, this is not necessarily the case. To find table filenode path, you can run the following query when you connected to your database:
select pg_relation_filepath('bar');
pg_relation_filepath
----------------------
base/17447/27741If you don't want the path but only the filenode then you can use the function pg_relation_filenode with the same argument. As for the database OID, you can find the table filenode by using oid2name
> oid2name -d foo -t bar
From database "foo":
Filenode Table Name
----------------------
27741 barThe System tables
In the previous section we talk a bit about system tables, it's interesting to know that there is a system catalog schema which contains tables that you may want to query to find extra information.
When you create a database, in addition to public and user-created schemas, each database contains a pg_catalog schema, which contains the system tables and all the built-in data types, functions, and operators. pg_catalog is always effectively part of the search path, so you don't need to use the prefix when you query the system tables.
Once connected to your database via psql, you can list the list the systems tables via:
\dt pg_catalog.*How the rows are stored
Every table stored as an array of pages of a fixed size (usually 8Kb). In a table, all the pages are logically equivalent, so a particular item (row) can be stored in any page.
The structure used to store the table is a heap file. Heap files are lists of unordered records of variable size. The heap file is structured as a collection of pages (or block), each containing a collection of items. The term item refers to a row that is stored on a page.
A page structure looks like the following:
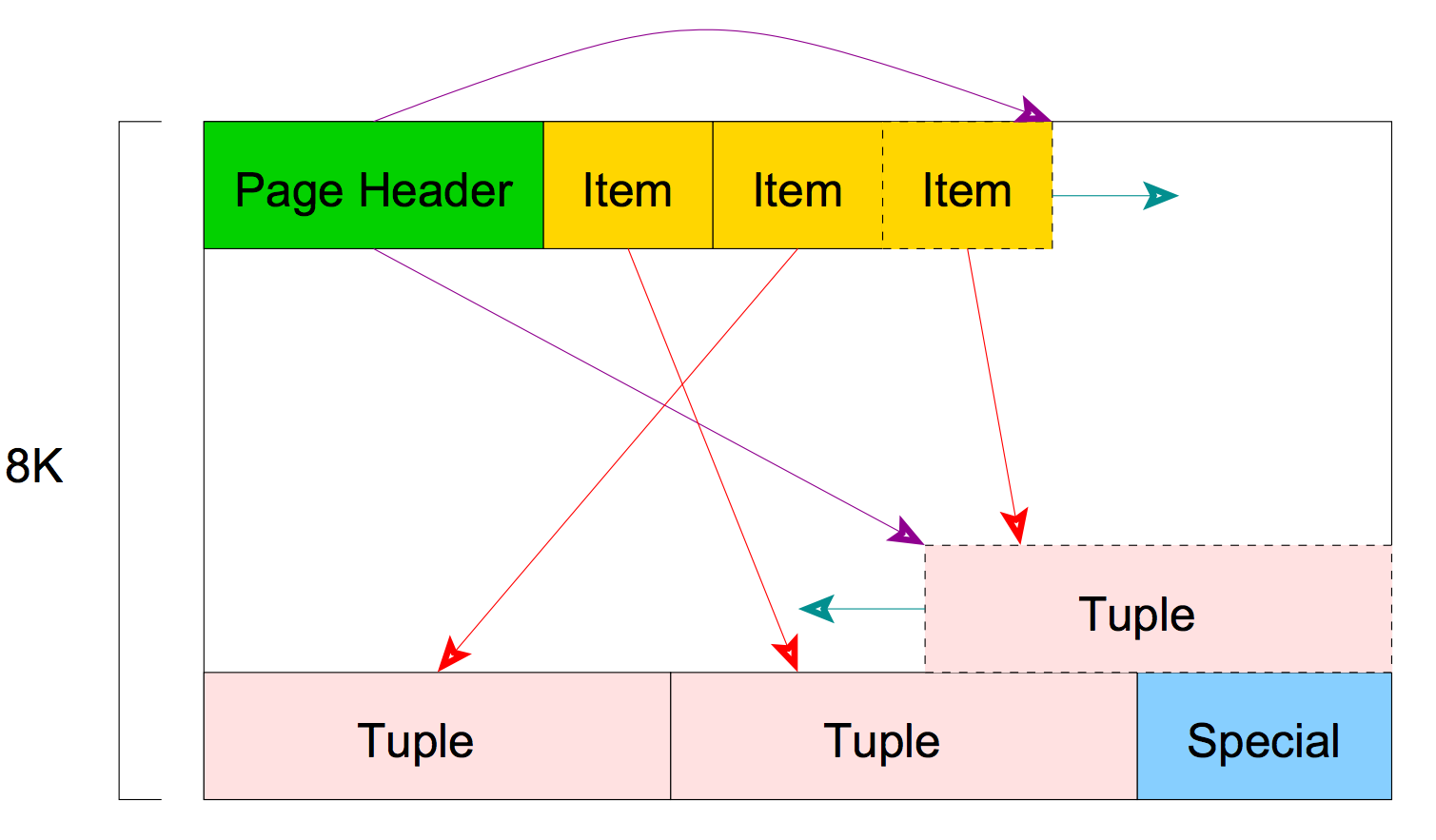
It contains some headers which we are not going to cover, but they provide info about checksum, start of free space, end of free space, ... Items after the headers is an array identifier composed of (offset, length) pairs pointing to the actual items.
Because an item identifier is never moved until it is freed, its index can be used on a long-term basis to reference an item, even when the item itself is moved around on the page to compact free space. A Pointer to an item is called CTID (ItemPointer), created by PostgreSQL, it consists of a page number and the index of an item identifier.
The items themselves are stored in space allocated backwards from the end of unallocated space. To summarize, inside a page the pointers to the row are stored at the starts and the tuples (rows) are stored at the end of the page.
You can access the CTID of a row by adding ctid in the selected columns:
SELECT ctid, * from bar;What are the limitations
According to About PostgreSQL, the max number of column is between 250 and 1600 depending on column types. The column types affect it because in PostgreSQL rows may be at most 8kb (one page) wide, they cannot span pages.
It doesn't mean that value of a column is limited to 8kb. Having a big value in columns is possible depending on the type because postgreSQL has a mechanism called TOAST which can handle that. There's still limit to how many columns you can fit in, that depends on how wide the data types used are. Even pointer to TOAST attribute still requires some bytes.
The Oversized-Attribute Storage Technique
In the previous section, we've said that some column can go beyond the size of a page if their types are TOAST-able. Let's do an overview of TOAST. First, TOAST stands for The Oversized-Attribute Storage Technique, probably the best acronym in the history of Computer Science.
PostgreSQL uses a fixed page size (commonly 8 kB), and does not allow tuples to span multiple pages. Therefore, it is not possible to store very large field values directly. When a row is attempted to be stored that exceeds this size, TOAST basically breaks up the data of large columns into smaller "pieces" and stores them into a TOAST table. Each table you create has its own associated (unique) TOAST table, which may or may not ever end up being used, depending on the size of rows you insert. All of this is transparent to the user and enabled by default. The mechanism is accomplished by splitting up the large column entry into 2KB bytes and storing them as chunks in the TOAST tables. It then stores the length and a pointer to the TOAST entry back where the column is normally stored. Because of how the pointer system is implemented, most TOAST'able column types are limited to a max size of 1GB.
TOAST has a number of advantages compared to a more straightforward approach such as allowing row values to span pages. The big values of TOASTed attributes will only be pulled out (if selected at all) at the time the result set is sent to the client. The table itself will much smaller and more of its rows fit in the shared buffer cache than would be the case without any out-of-line storage (TOAST). It's also more likely that the sort sets get smaller which imply having sorts being done entirely in memory.
In our example, the table bar with the OID of 27741 will have the TOAST table pg_toast_27741. There is more to be said about TOAST like that it also provide compression, but I keep it to the essential. TOAST make it transparent to the user but keep in mind that TOAST-able column have a limit 1GB. You can store a lot of data in 1GB and it can be useful to denormalize data in an ARRAY type or store documents in JSONB type.
Free Space map
Each table has a free space map, which stores information about free space available in the relation. The free space map is stored in a file named with the filenode number plus the suffix _fsm.
The values stored in the free space map are not exact. They're rounded to a precision of 1/256th of page size (32 bytes with default 8kb), and they're not kept fully up-to-date as tuples are inserted and updated. Some operations update the freespace map as deleting all the rows, but the VACCUM will update the freespace map for the future row being able to know which page they can fit.
The freespace map is updated by running VACUUM because an UPDATE or DELETE of a row does not immediately remove the old version of the row. This approach is necessary to gain the benefits of multiversion concurrency control (MVCC): the row version must not be deleted while it is still potentially visible to other transactions. But eventually, an outdated or deleted row version is no longer of interest to any transaction. The space it occupies must then be reclaimed for reuse by new rows, to avoid unbounded growth of disk space requirements.
The standard form of VACUUM removes dead row versions in tables and marks the space available for future reuse. However, it will not return the space to the operating system, except in the special case where one or more pages at the end of a table become entirely free and an exclusive table lock can be obtained. It doesn't mean that the free space inside a page is fragmented, VACUUM rewrites the entire block, efficiently packing the remaining rows and leaving a single contiguous block of free space in a page.
In contrast, VACUUM FULL actively compacts tables by writing a complete new version of the table file with no dead space. This minimizes the size of the table, but can take a long time. It also requires extra disk space for the new copy of the table, until the operation completes. The goal of routine VACUUM is to avoid needing VACUUM FULL. The idea is not to keep tables at their minimum size, but to maintain steady-state usage of disk space: each table occupies space equivalent to its minimum size plus how much space gets used up between vacuumings.
In Past, when VACUUM ran, it had to look at every tuple in a table, because there was no information about which pages may not have been updated since the last VACUUM. PostgreSQL introduced the visibility map, VACUUM is now be able to perform partial scans of table data, skipping pages which are marked as fully visible. Partial scans mean fewer I/O operations for VACUUM.
You can query the frees pace available by pages in your table via following query:
CREATE EXTENSION pg_freespace;
SELECT * FROM pg_freespace('bar'::regclass);Visibility map
Each table has also a Visibility Map (VM) to keep track of which pages contain only tuples that are known to be visible to all active transactions. In others words, to track which pages are known to have no dead row. The Visibility map is stored alongside the table file in a separate file, named after the filenode number of the relation, plus a _vm suffix. For example, the filenode of a relation bar is 27741, the VM is stored in a file called 12345_vm, in the same directory as the main relation file.
We've seen in the previous section, the dead rows are due to the MVCC mechanism.
The visibility map simply stores one bit per heap page. A set bit means that all tuples on the page are known to be visible to all transactions. This means that the page does not contain any tuples that need to be vacuumed. The map is conservative in the sense that we make sure that whenever a bit is set, we know the condition is true, but if a bit is not set, it might or might not be true. Visibility map bits are only set by vacuum but are cleared by any data-modifying operations on a page.
What about Indexes
Indexes are also stored as files too and in the same directory as the tables. Indexes are an other story, I didn't cover them as it will make this post much longer. Even if indexes also have pages, they follow a different structures as they are b-tree's (by default).
Want to work on challenging projects using Postgres?
If you are interested in working with Postgres on some interesting projects, come join me at Opendoor. We heavily use PostgreSQL for Data Processing, Web Development, Data Warehousing, ETLs, Data Science, and Geo Analysis. We are always looking for passionate Engineers and Data Scientists to join our team. Please reach out to our recruiter, Ryan or apply via our job page
Conclusion
I hope this post gave you enough information to have a better understand about how PostgreSQL may store your data. It has been useful for me to dive in the subject, it makes some other concepts or talks more easy to grasp but mainly fewer behaviors have to be accepted for granted. Much more could be said about PostgreSQL store and I hope that we will see more posts like this to make PostgreSQL internal parts understandable to beginners.